



Ever since I first launched One Word Domains this summer, I've received plenty of requests for a search feature to help navigate the ever growing list of domains on the site (the current number is about 500K domains).
My first thought when I started planning the implementation of this feature was:
Oh, this shouldn't be too hard, I'm just gonna:
- Get the list of words that are the most similar to the user's search query using the spaCy NLP library and display them on the site.
- Also show the list of TLDs that are available for that particular query.
No biggie.
However, when I started translating my vision to code, I ran into a few technical constraints.
First, I wanted the search to be blazing fast, so calculating the cosine similarity in real-time is a no-go – that would simply take too long.
Also, even if I were able to optimize the calculation time to <50ms, how do I deploy the spaCy model to the web when even the en_core_web_md model itself is over 200MB unzipped?
It took me 3 whole days to figure out a viable solution for this, which is why I'm hoping this blog post will ohelp you do so in much shorter time.
Building A Word Association Network
After doing a bunch of research, I came to the conclusion that there was only one way for me to reduce the search time to sub-50ms levels – by pre-training the model locally and caching the results in PostgreSQL.
Essentially, what I'd be doing is building out a word association network that maps the relationship between the 20K words that are currently in my database.
Picture this:
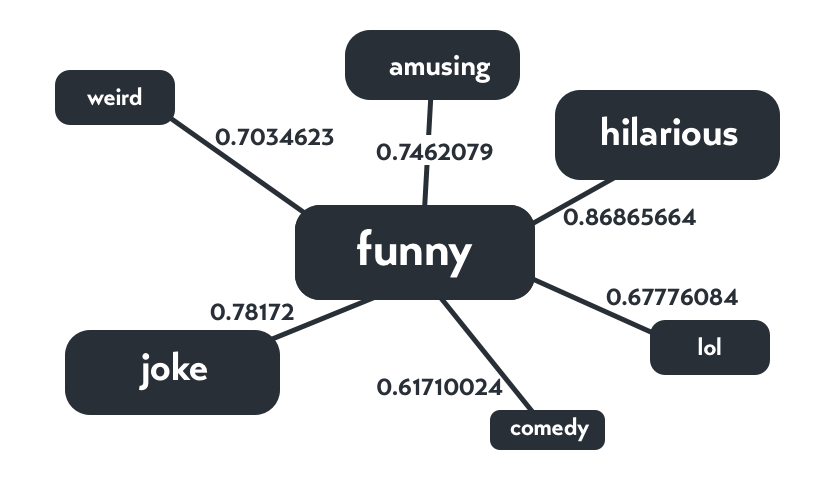
Note: the decimal values on each of the edges represent the similarity scores between the auxiliary terms and the root term
Now picture that again, but this time with 20,000 adjectives, nouns, verbs, and 10 other categories + French and Spanish words*.
I know, sounds pretty crazy and cool at the same time, right?
First, I installed the spaCy library in my virtual environment and downloaded the en_core_web_md model:
pip install spacy
python3 -m spacy download en_core_web_md
Then, I imported them into my Flask app and loaded up the word vectors:
import spacy
import en_core_web_md
nlp = en_core_web_md.load()
Now it's time to build the word association model. I first took the list of vocabs that were on One Word Domains and tokenized them. Then, by using a nested for-loop, I calculated the cosine similarities between each of the terms, preserved a list of the top 100 most similar auxiliary terms for each word using the addToList function, and stored everything in a dictionary. The code for all that is as follows:
# Add to list function to add the list of significant scores to list
def addToList(ele, lst, num_ele):
if ele in lst:
return lst
if len(lst) >= num_ele: #if list is at capacity
if ele[1] > float(lst[-1][1]): #if element's sig_score is larger than smallest sig_score in list
lst.pop(-1)
lst.append((ele[0], str(ele[1])))
lst.sort(key = lambda x: float(x[1]), reverse=True)
else:
lst.append((ele[0], str(ele[1])))
lst.sort(key = lambda x: float(x[1]), reverse=True)
return lst
import json
# list of English vocabs
en_vocab = ['4k', 'a', 'aa', ...]
# tokenizing the words in the vocab list
tokens = nlp(' '.join(en_vocab))
# initiate empty dictionary to store the results
en_dict = {}
# Nested for loop to calculate cosine similarity scores
for i in range(len(en_vocab)):
word = en_vocab[i]
print('Processing for '+ word + ' ('+ str(i) + ' out of '+ str(len(en_vocab)) + ' words)')
for j in range(i+1, len(en_vocab)):
prev_list_i = en_dict[str(tokens[i])]['similar_words']
en_dict[str(tokens[i])]['similar_words'] = addToList((str(tokens[j]), tokens[i].similarity(tokens[j])), prev_list_i, 100)
prev_list_j = en_dict[str(tokens[j])]['similar_words']
en_dict[str(tokens[j])]['similar_words'] = addToList((str(tokens[i]), tokens[i].similarity(tokens[j])), prev_list_j, 100)
with open('data.json', 'w') as f:
json.dump(en_dict, f)
This code took forever to run. For 20,000 words, there were a total of 200,010,000 combinations (20000 + 19999 + 19998 +...+ 3 + 2 + 1 = 20001 * 10000 = 200,010,000). Given that each combination took about half a millisecond to complete, it wasn't a surprise when the whole thing took about 36 hours to execute completely.
But, once those gruelling 36 hours were up, I had a complete list of words along with 100 most similar words for each and every one of them.
To improve data retrieval speeds, I proceeded to store the data in PostgreSQL – a relational database that is incredibly scalable and powerful especially when it comes to large amounts of data. I did that with the following lines of code:
def store_db_postgres():
with open('data.json', 'r') as f:
data = json.load(f)
for word in data.keys():
db_cursor.execute("""INSERT INTO dbname (word, param) VALUES (%s, %s);""", (word, json.dumps(data[word]['similarity'])))
db_conn.commit()
return 'OK', 200
And, voilà! You can now traverse the millions edges in the word association network at minimum latency (last I checked, it was at sub-50ms levels). The search tool is live on One Word Domains now – feel free to play around with it.
*The French and Spanish words were trained on the fr_core_news_md and es_core_news_md models respectively.
Deploying to the Cloud
Here comes the tricky part. I knew that while I had over 20K of the most commonly-used English words in my word association network, there's always gonna be a chance where a user's query is not part of my knowledge base.
Therefore, I wanted to add an option for users to generate results on the fly. To do that, I needed to upload the spaCy model to the web so that I can build additional edges to the word association network in real-time.
However, this wasn't possible on Heroku given the 500MB slug size hard limit (my current slug size was already 300MB). I needed a more powerful alternative, and that's when I decided to go with AWS Lambda.
I had my first encounter with Lambda function s when I had to use them to host the NLP component of a movie chatbot that I helped built for my AI class this fall.
While Lambda functions were rather complicated to set up in the beginning, with the help of the handy Zappa library and tons of StackOverflow posts, I was able to build One Word Domains' very own lambda function that would find the most similar words for a given query and return them in JSON format.
I won't go too deep into the weeds about the deployment process, but this was the guide that helped me immensely. Also, here's the main driver function that would find the list of the top 100 most closely associated words for a given query:
@app.route('/generate')
@cross_origin()
def generate_results():
# get vocab
vocab_pickle = s3.get_object(Bucket='intellisearch-assets', Key='vocab')['Body'].read()
vocab_only = pickle.loads(vocab_pickle)
vocab_only = list(set(vocab_only))
# add new query to vocab
vocab_only.insert(0, query)
# store vocab back to pickle
serialized_vocab = pickle.dumps(vocab_only)
s3.put_object(Bucket='intellisearch-assets', Key='vocab', Body = serialized_vocab)
# do the rest
tokens = nlp(' '.join(vocab_only))
results = []
for i in range(1, len(vocab_only)):
if str(tokens[i]) != query:
results.append([str(tokens[i]), tokens[0].similarity(tokens[i])])
results.sort(key=lambda x: x[1], reverse=True)
return results[:100]
Here, I'm storing the list of vocabs in the form of a pickle file on AWS S3, and whenever I have a new query, I use s3.get_obect to retreive the list and update them by inserting the new word into the list. Note that I'm using the @cross_origin() decorator from Flask's CORS library since I'll be calling on this Lambda function from my Heroku app.
And that's...pretty much it. All I had to do now was connect the AWS Lambda API endpoint to my original Heroku app to help generate a list of relevant words for a given search query that a user enters on the site. Here's the outline for that:
import requests
url = "https://my-api-endpoint.amazonaws.com/generate?query=" + query
response = requests.get(url)
similar_words = response.json()
print(similar_words)
Finally, the moment of truth:
And there you go – a fully-functional search algorithm built on top of a word association network containing 20,000 nodes and millions of edges.
Feel free to play around with the search tool at the top of every page on One Word Domains. If you have any feedback, or if you find a bug, feel free to send me a message via chat, contact page, email or Twitter – I'd love to help!


